数据开发
定义
本模块用于统一管理与执行实时和离线的数据处理任务,支持多种数据源类型、调度执行方式以及任务运行控制能力,是数据中台核心的数据流编排与加工工具。
实时数据开发任务
支持通过 Flink 等流处理框架实现对接入数据的实时采集、处理与输出,任务支持热更新与在线管理。
核心能力:
- ✅ 任务管理:支持新增、编辑、启用、禁用、立即执行、查看日志等操作;
- 🔄 状态更新机制:系统重启后自动恢复任务状态,保持任务不中断;
- 🧰 执行模板:按执行器类型(如 Flink、SQL、CDC)预置模板供快速配置;
- 🗂️ 数据源支持:
- 输入支持:MySQL(CDC)、Oracle、达梦、Hive、Kafka 等;
- 输出支持:MySQL、Oracle、达梦、Hive、Kafka 等;
- 🧪 调试与控制:支持任务调试时停止、运行中任务手动停止;
- 🔚 自动关闭:支持任务运行后缺失关闭逻辑的补齐优化;
- 🔗 已完成前后端接口联调,实现任务运行状态与执行反馈联通。
离线数据开发任务
基于 Spark SQL 或各类数据库执行引擎,支持批处理任务的开发、调度与执行,用于日常数据加工、模型计算、数据清洗等处理流程。
核心能力:
- 💡 支持多种数据源的 SQL 编写、调试与存储过程;
- ⚙️ 适配 Spark SQL 引擎,可执行复杂 SQL 与存储过程;
- 📤 可配合数据集成任务、资产输出任务等进行链式加工。
注意事项
实时任务建议结合 Kafka 分区策略、Flink 并行度进行性能优化;离线任务应合理配置资源队列与调度优先级,避免调度拥塞。
作用范围
面向数据研发、开发工程师等角色,支持基于 Flink 和 Spark 等引擎进行 SQL 任务开发,覆盖实时流处理与离线批处理两类场景。适用于数据同步、数据计算、数据入湖等场景。
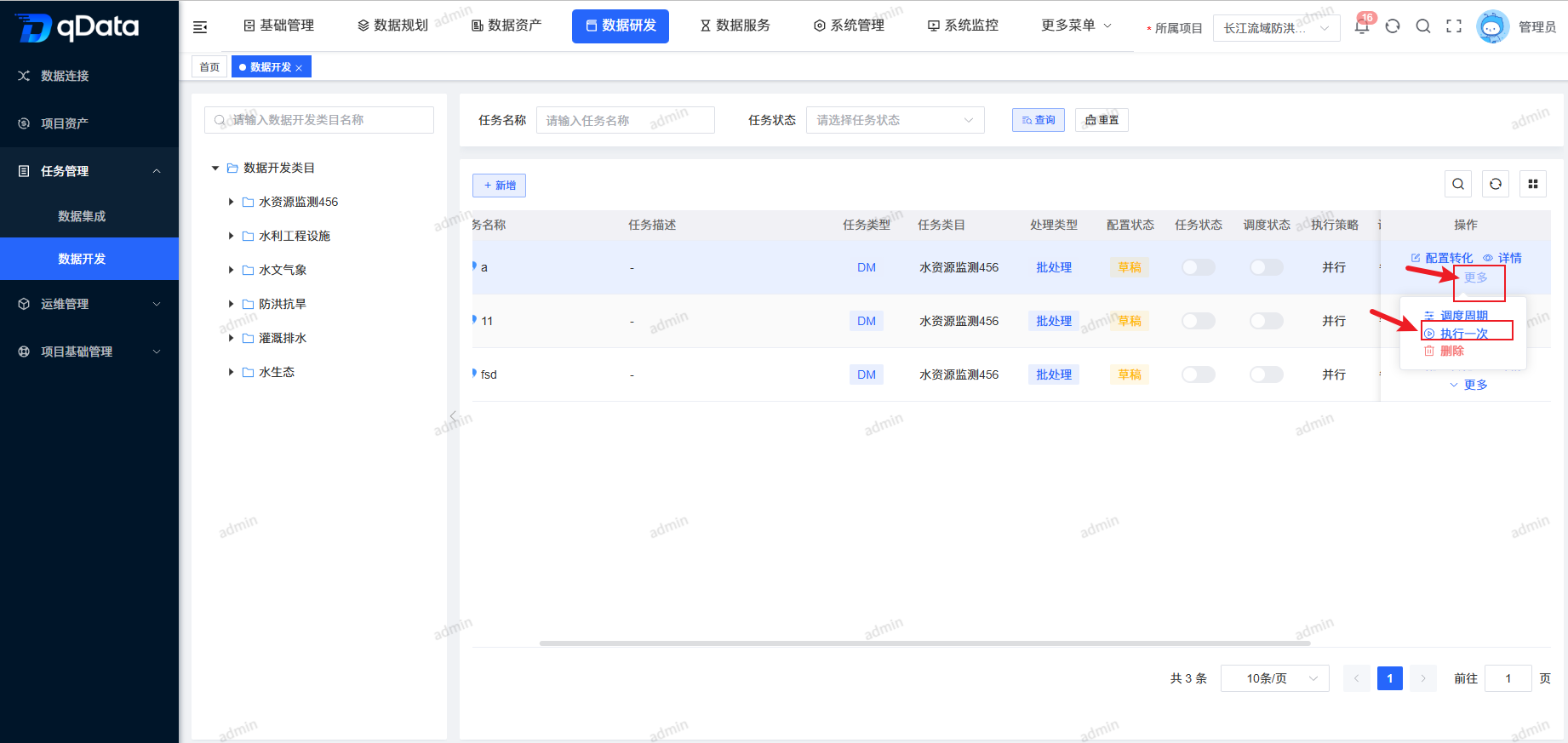
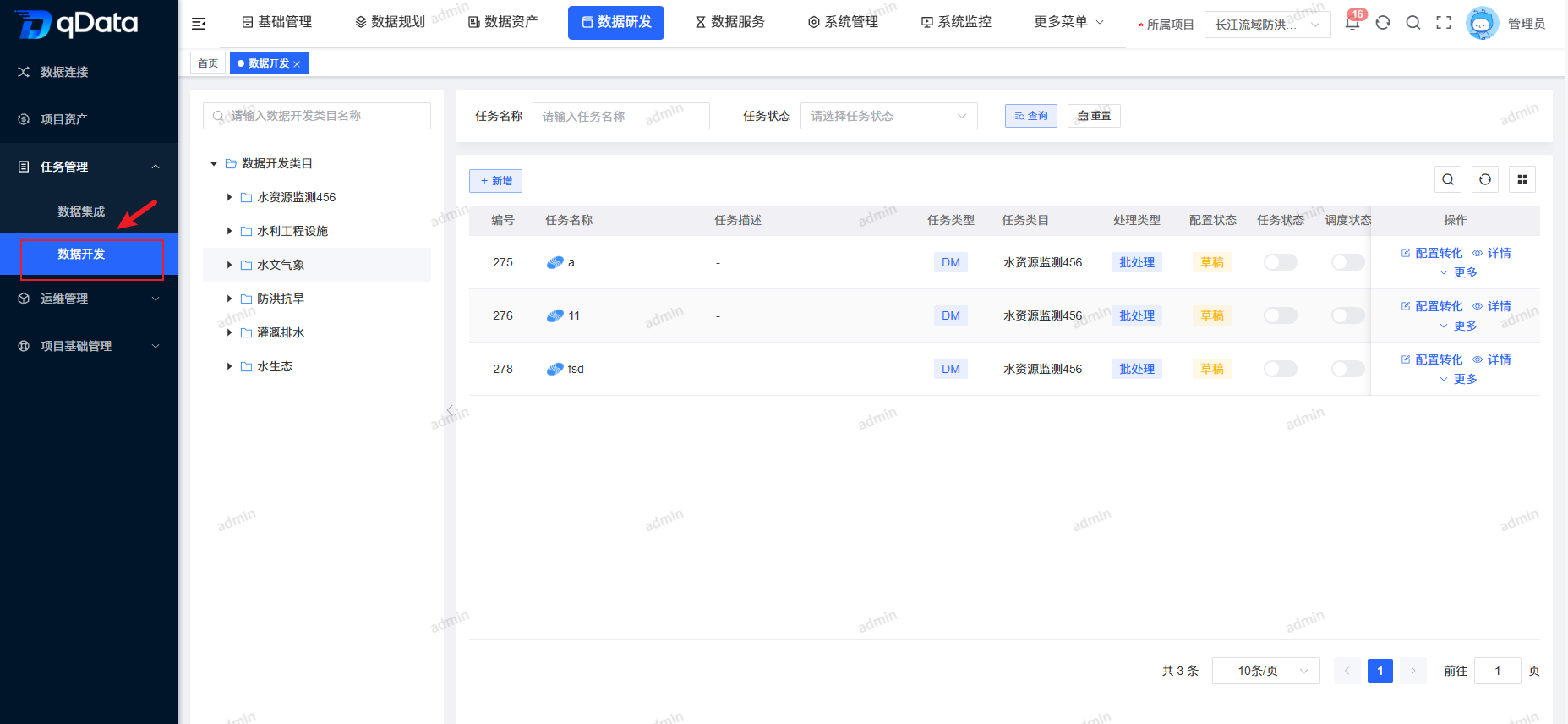
1、数据开发页面
点击【数据研发】-> 【任务管理】下的【数据开发】,进入数据开发页面。页面采用左右布局:左侧以树形结构展示数据开发类目,右侧展示任务列表包含任务名称、任务描述、任务类目、任务状态、调度状态等字段。
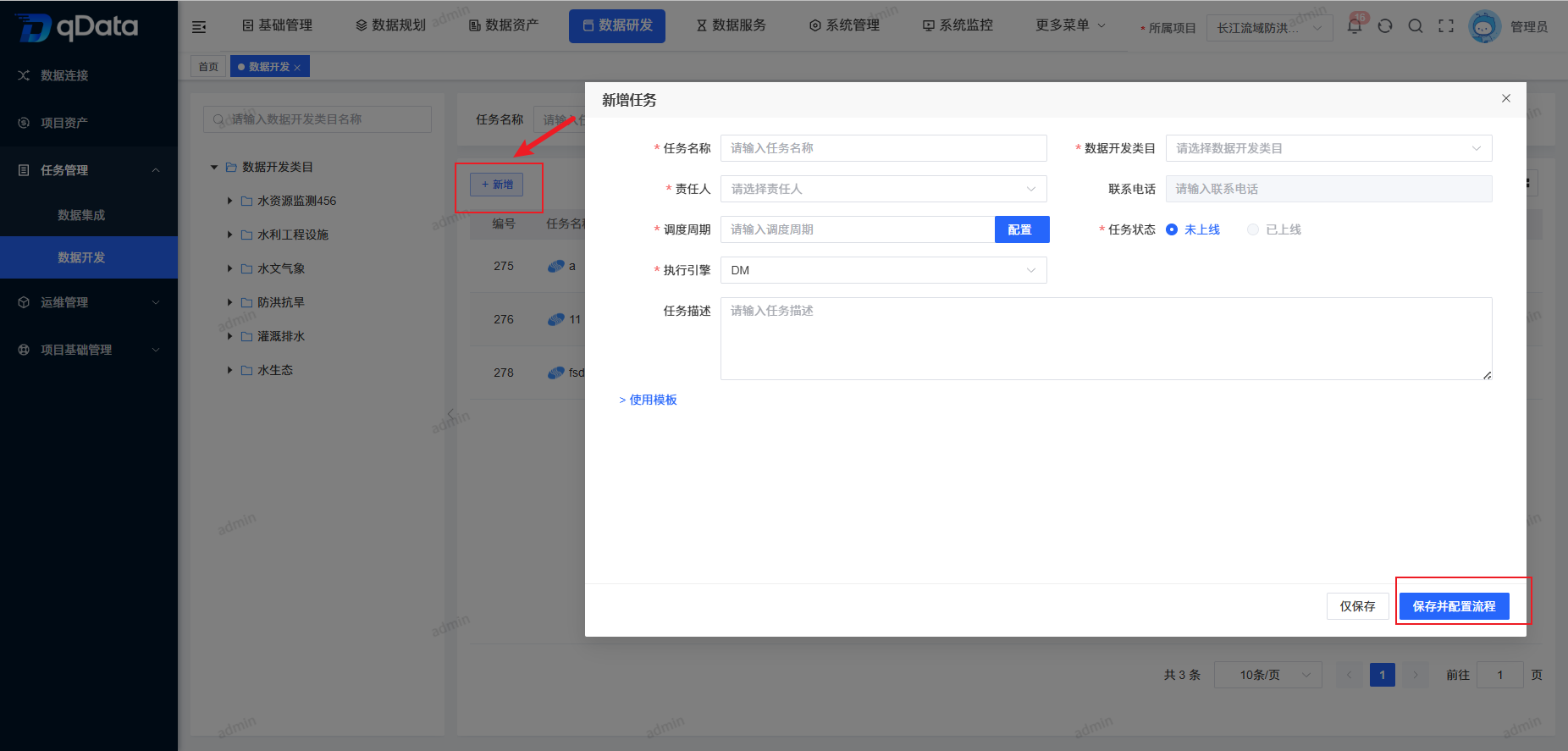
2、新增数据开发任务
点击页面中【新增】按钮,在出现的弹出框内填写主题信息,并点击【确定】按钮,完成新增数据开发任务新增。
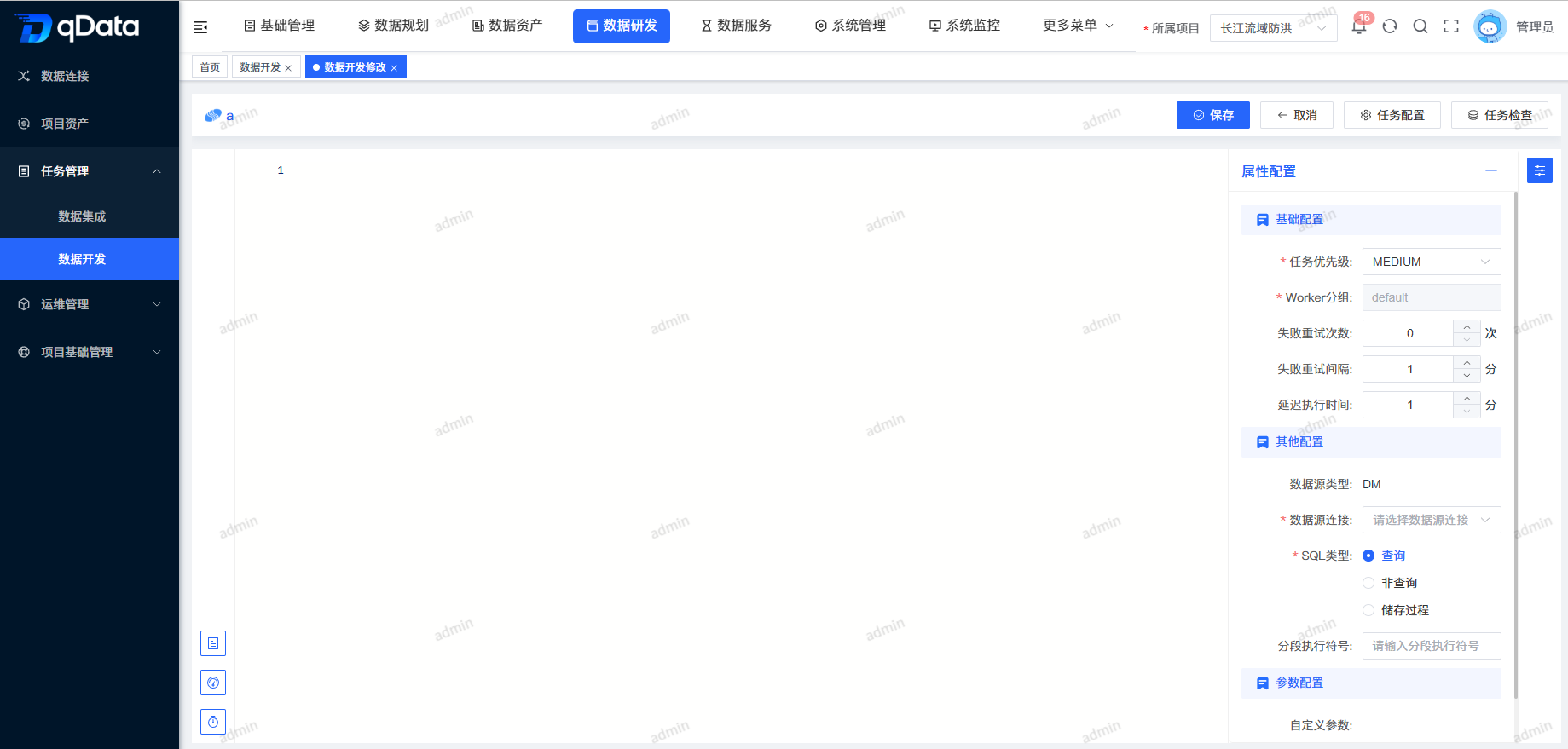
3、配置转化数据开发任务
选择需配置转化数据开发任务,在操作列中点击【配置转化】按钮,在出现的页面中编辑转换规则,并点击【保存】按钮,完成配置转化数据开发任务。
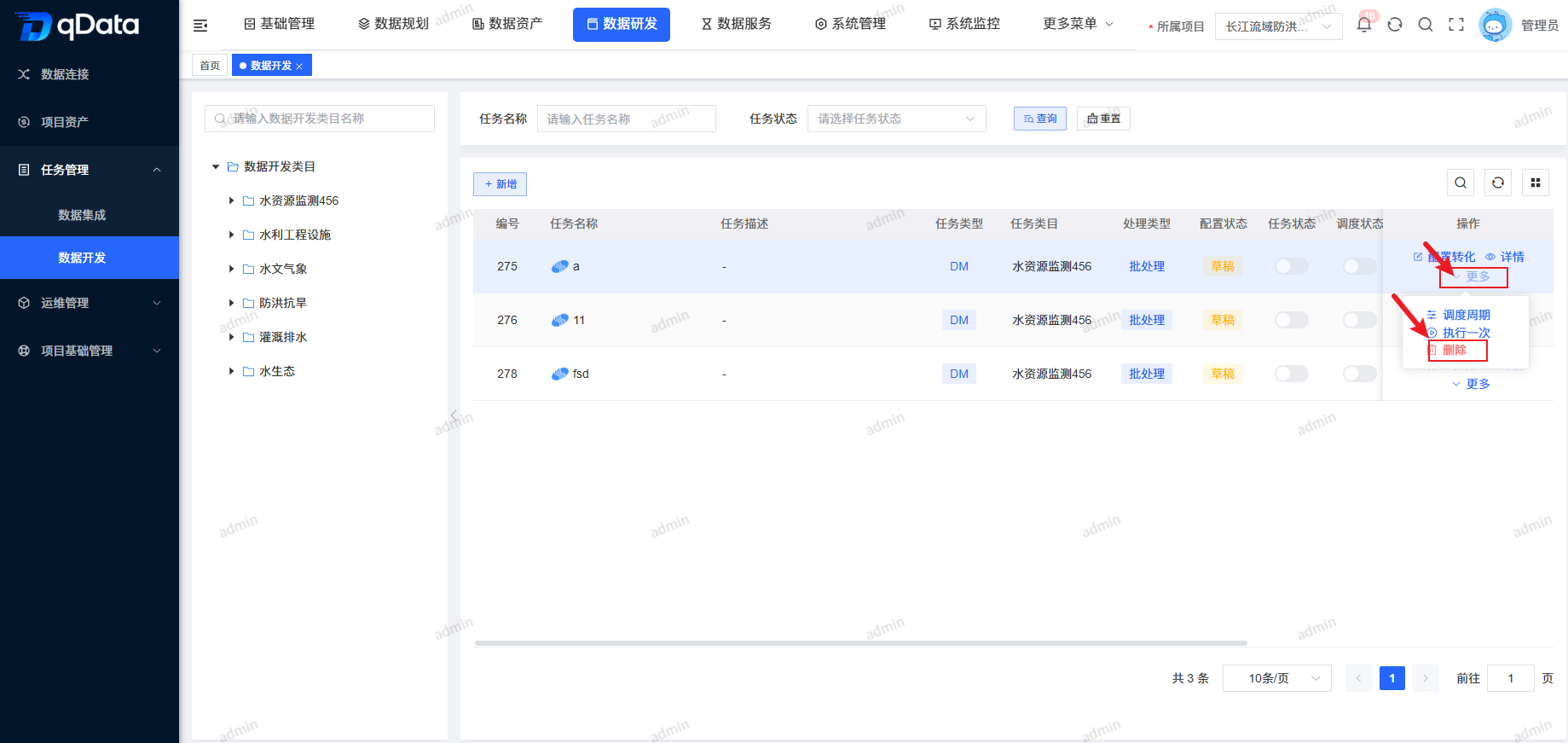
4、删除数据开发任务
选择需删除数据开发任务,点击操作列中的【更多】->【删除】按钮,并点击【确定】按钮,系统将删除该数据开发任务。
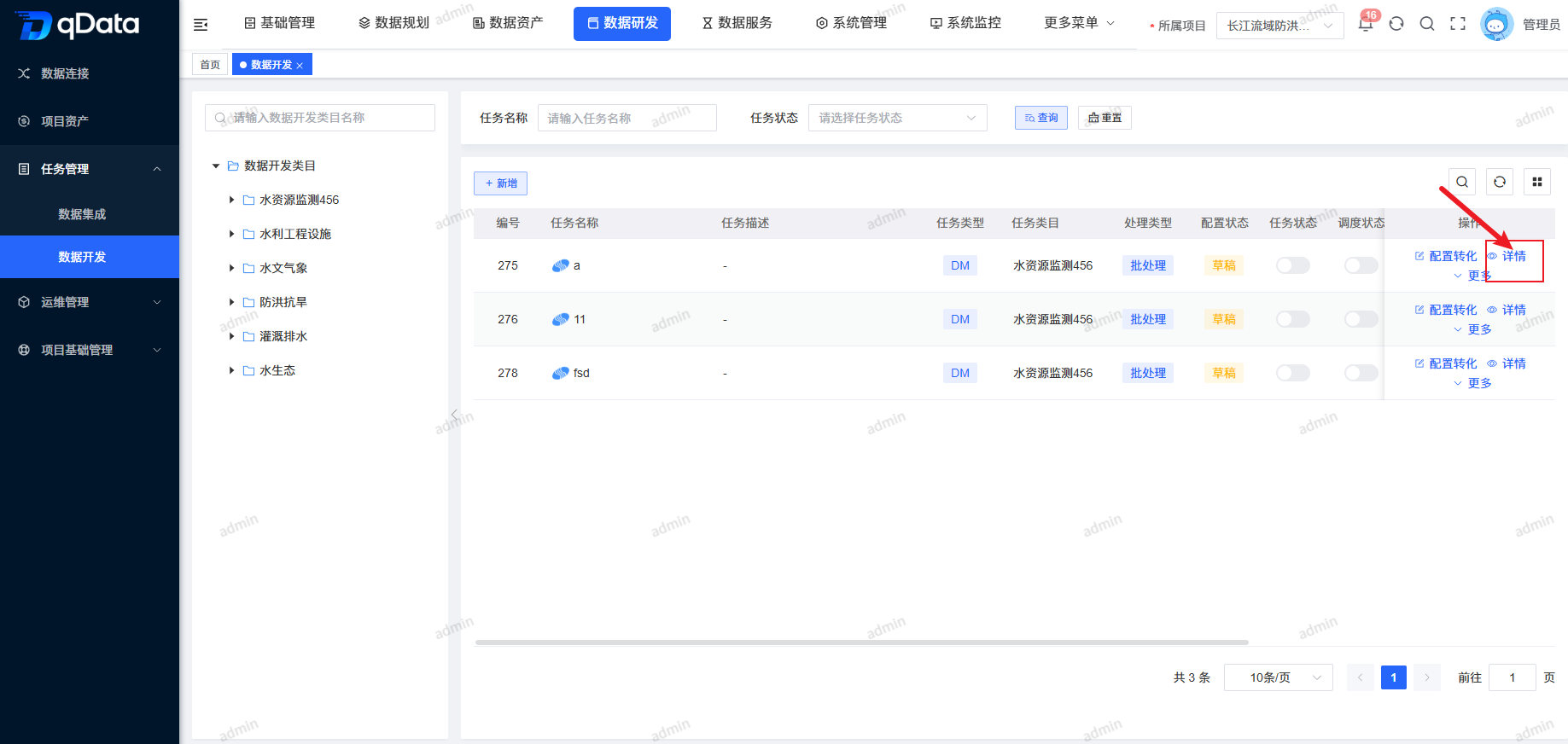
5、数据开发任务详情
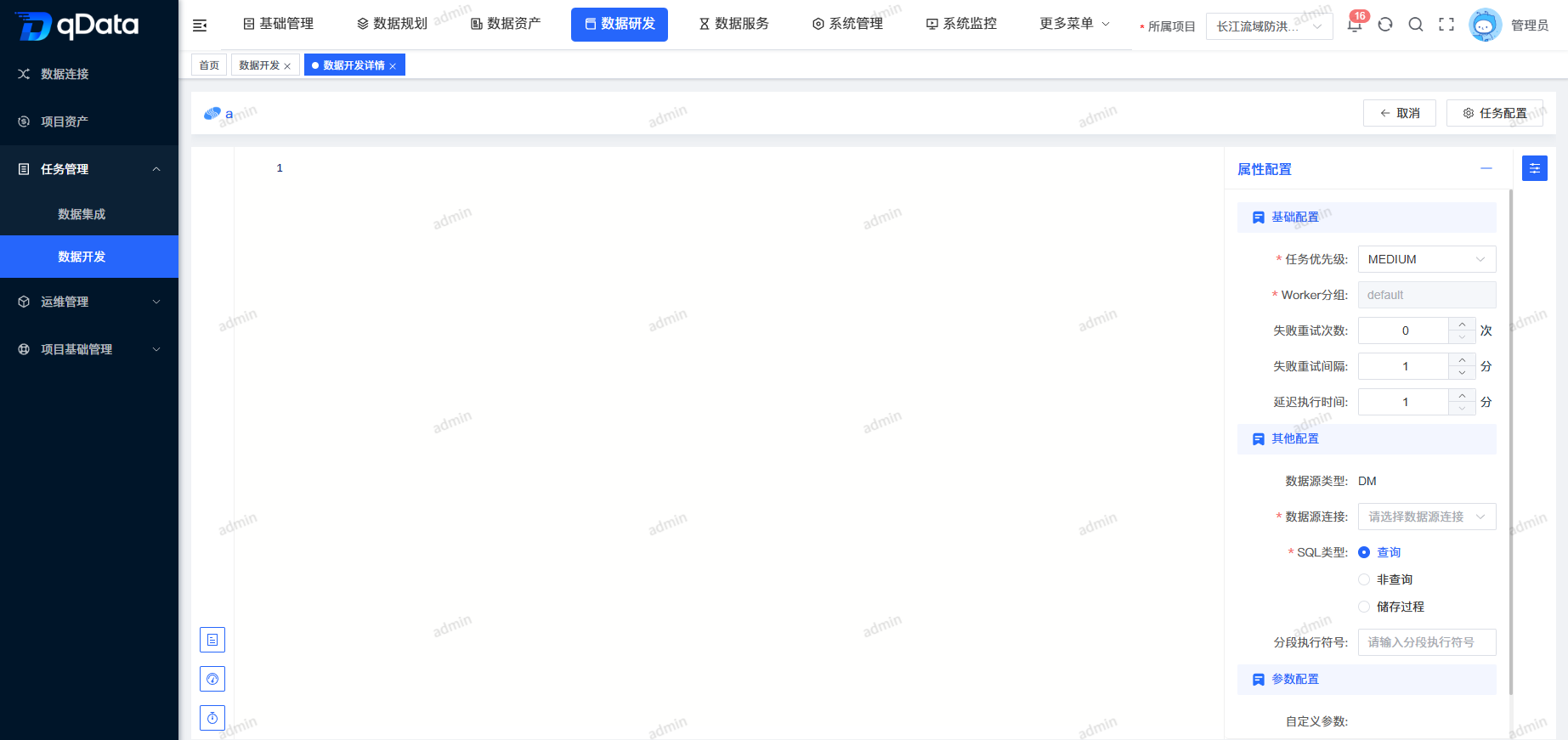
选择需查看数据开发任务详情,点击操作列中的【详情】按钮,进行数据开发任务详情查看。
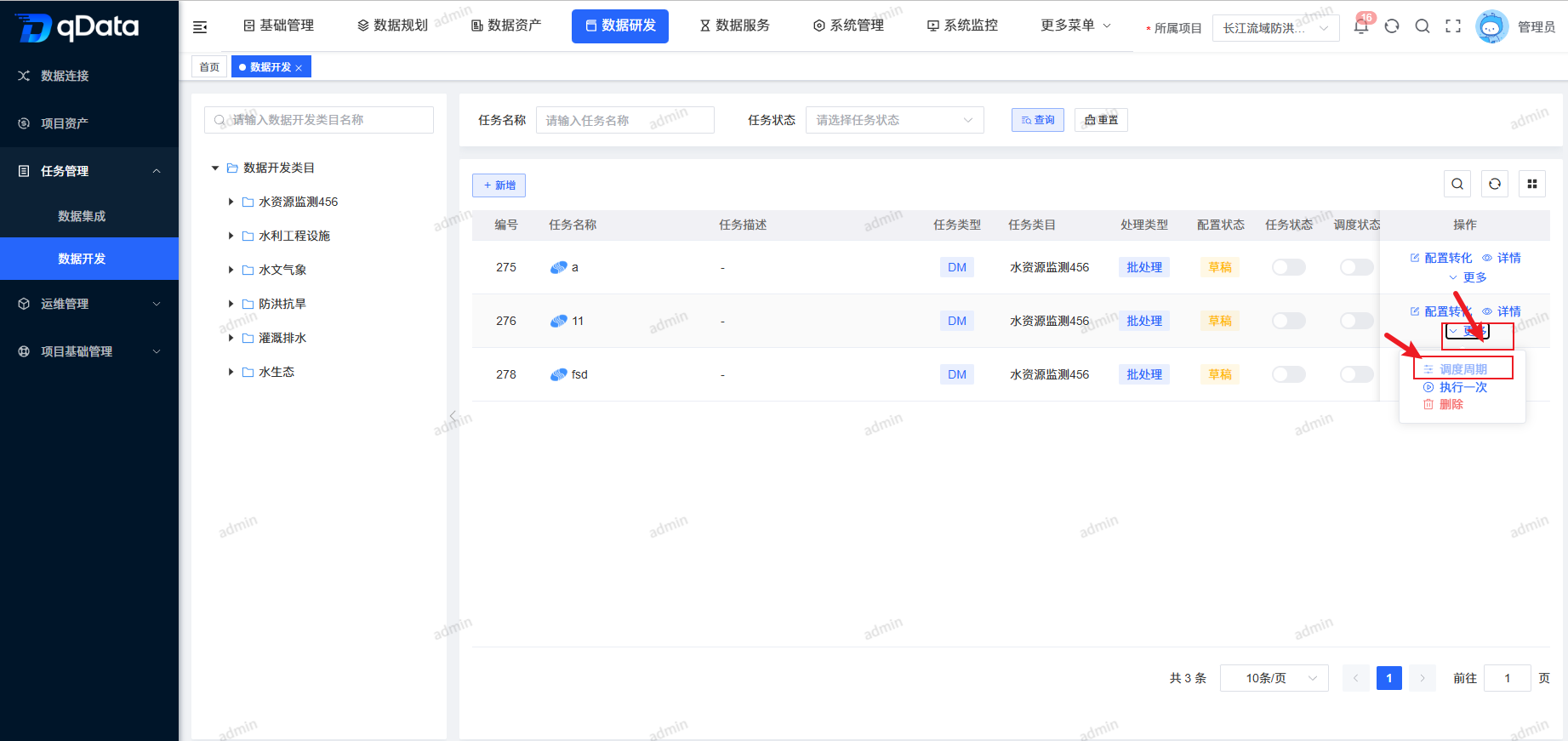
6、调度周期
选择需任务调度与执行的数据开发任务,点击操作列中的【更多】->【调度周期】按钮,在弹出框内填写相关信息,并点击【确定】按钮,系统将调度执行该数据开发任务。
7、任务状态
选择需上线/下线的任务状态,在状态列中点击【开关】按钮,即可完成上线/下线操作。
8、调度状态
选择需上线/下线的调度状态,在状态列中点击【开关】按钮,即可完成上线/下线操作。
9、执行一次
选择需执行一次的数据开发任务,点击操作列中的【更多】->【执行一次】按钮,系统将执行一次该任务,并提示相关信息。