数据集成
定义
本模块用于配置与执行数据集成(ETL)任务,支持多源数据的接入、转换与写出,是构建数据流、数据处理链路的核心组件。通过节点式图形化配置,用户可完成从数据读取、清洗、转换到落地的完整流程。
输入节点支持
- 🗄️ 关系型数据库表输入(MySQL、Oracle、SQL Server、达梦等);
- 🐝 Hive、Doris 等表输入;
- ⚡ Kafka 消息流接入(流式处理);
- 📁 HDFS 目录输入(支持 CSV、TXT 等格式);
- 🌐 API 输入组件(当前支持 JSON 对象作为输入)。
输出节点支持
- 🗄️ 表输出(写入关系型数据库);
- 🐝 Hive 表输出;
- 📁 写入 HDFS。
转换节点支持(持续增强中)
- 已完成组件:字段选择、字段重命名、值映射、字符串替换、增加常量、数值范围、字符串操作、设置字段值等;
- 已规划组件:字段拆分为多行、字符串剪切、字段设为常量、基于字段值设定序列、双流 Join 合并、行扁平化等(部分已完成 UI);
- 所有组件将持续适配主流数据库,保持与数据质量任务的转换能力一致。
特性增强
- ✅ 支持 Flink 实时任务模式,在保留原有离线调度能力基础上,支持流批一体的集成处理;
- 🔁 支持类 Kettle 多节点风格的图形化配置,可灵活添加多个转换节点,实现复杂转换逻辑编排;
- 🧩 转换组组件已重构界面交互,统一风格与质量任务规则配置方式,支持配置数十种清洗规则。
注意事项
请合理配置数据源权限及执行频率,避免对源系统产生过高负载;流式任务应结合 Kafka 消费策略和 Flink 执行计划进行稳定性评估。
作用范围
适用于结构化、半结构化及流式数据的集成处理场景,广泛应用于数据归集、数据治理、数据入湖入仓等关键链路中。适配多种数据源与目标端,支持规则驱动的数据转换及清洗。
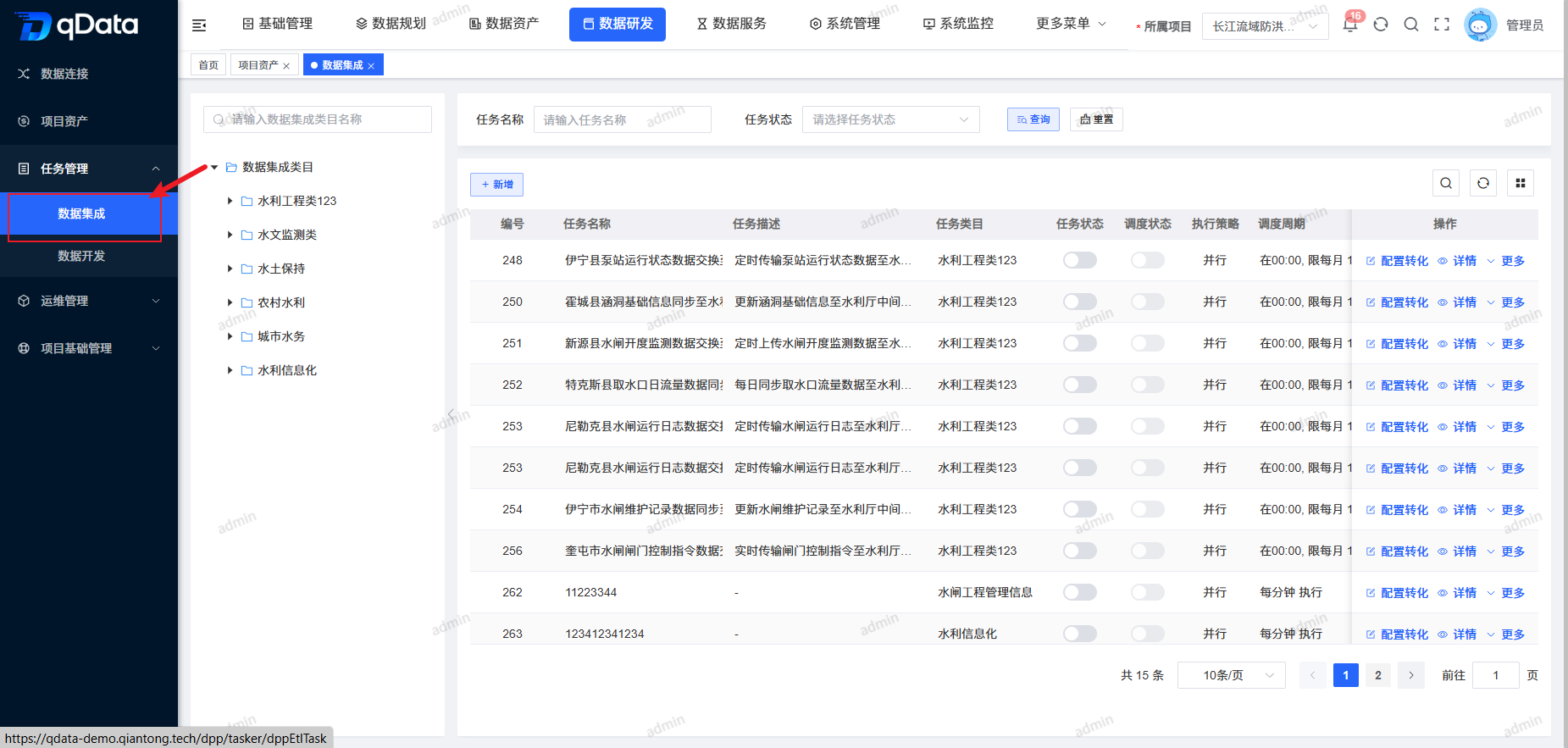
1、数据集成页面
点击【数据研发】-> 【任务管理】下的【数据集成】,进入数据集成页面。页面采用左右布局:左侧以树形结构展示数据集成类目,右侧展示任务列表包含任务名称、任务描述、任务类目、任务状态、调度状态等字段。
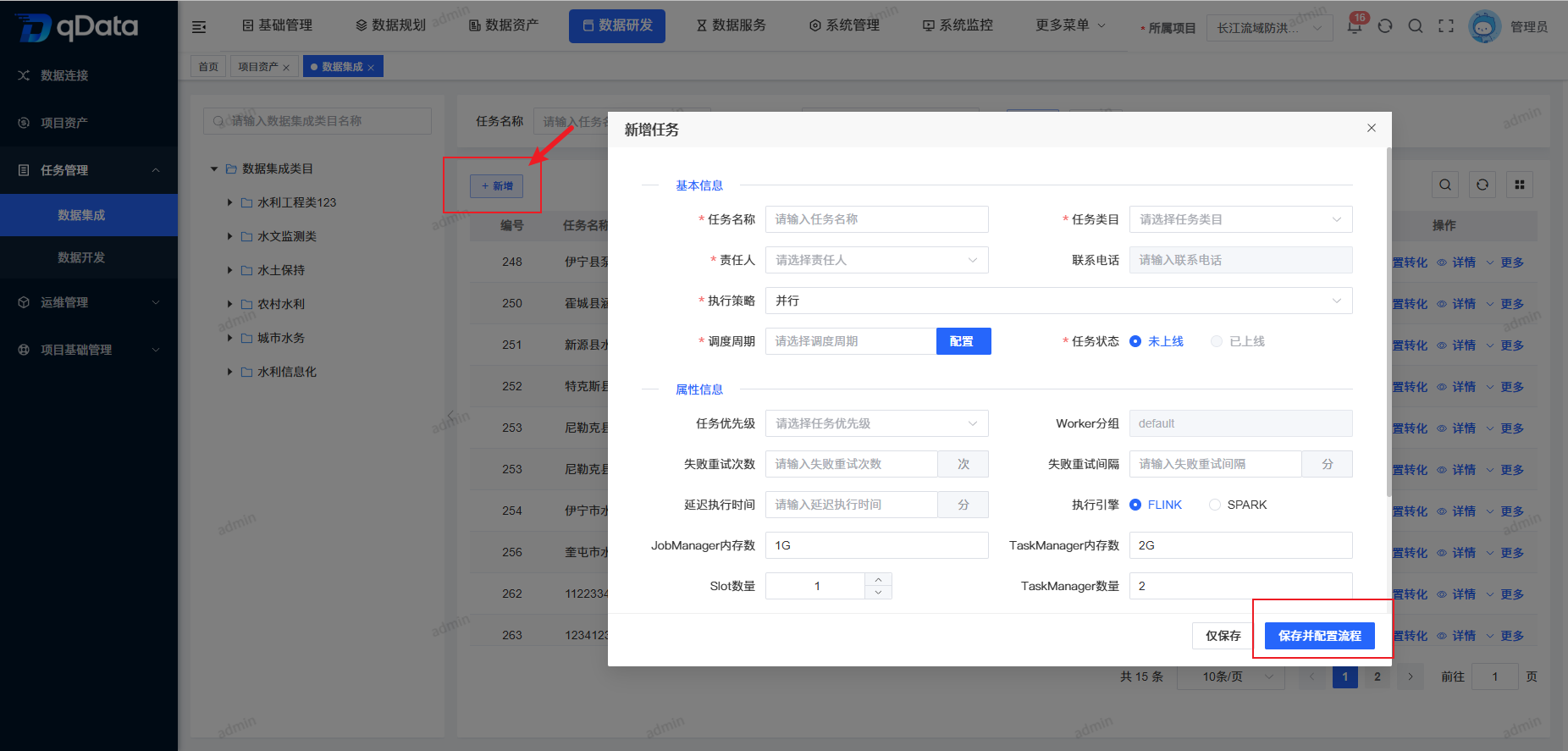
2、新增数据集成任务
点击页面中【新增】按钮,在出现的弹出框内填写主题信息,并点击【确定】按钮,完成新增数据集成任务新增。
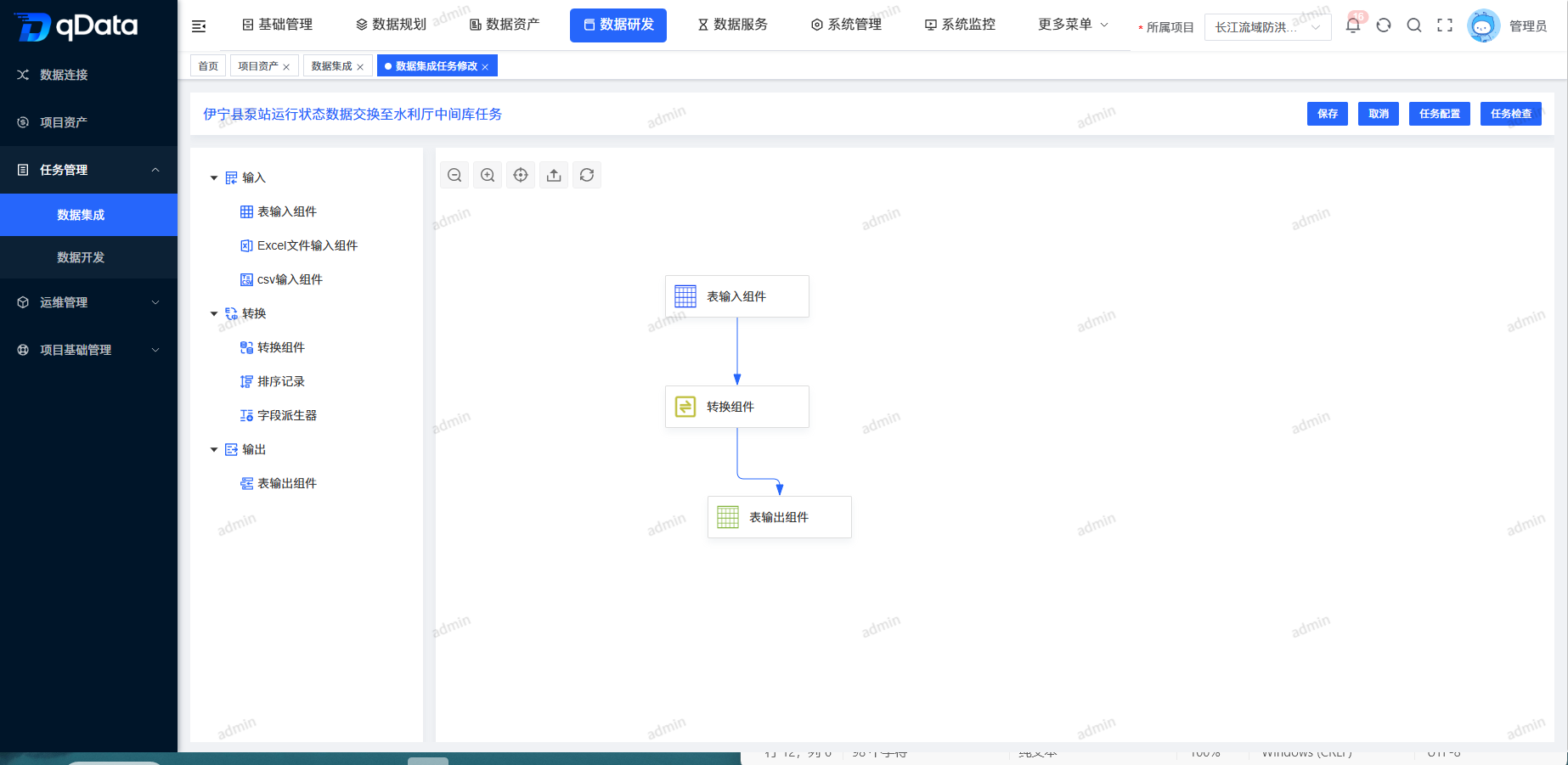
3、配置转化数据集成任务
选择需配置转化数据集成任务,在操作列中点击【配置转化】按钮,在出现的页面中编辑转换规则,并点击【保存】按钮,完成配置转化数据集成任务。
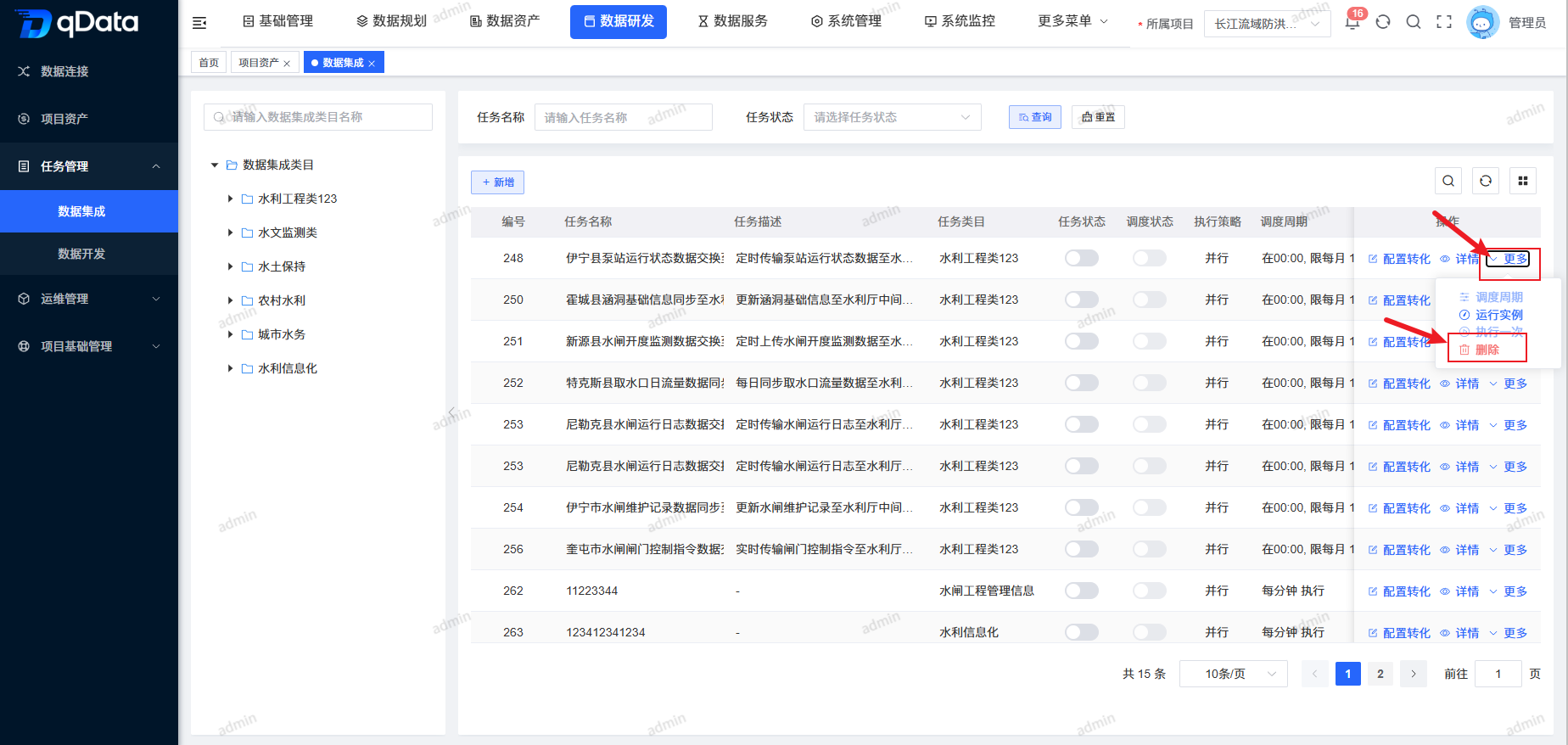
4、删除数据集成任务
选择需删除数据集成任务,点击操作列中的【更多】->【删除】按钮,并点击【确定】按钮,系统将删除该数据集成任务。
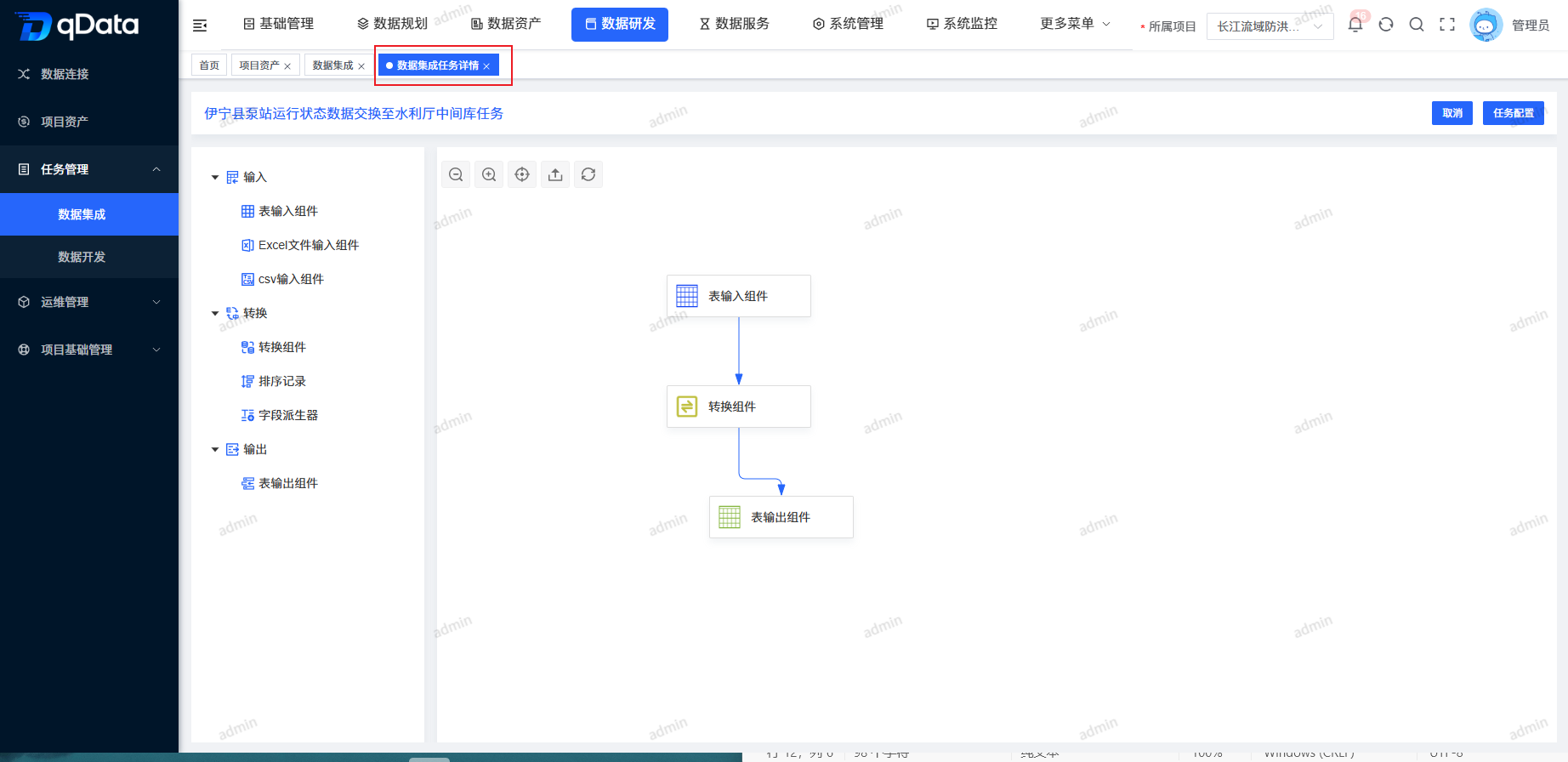
5、数据集成任务详情
选择需查看数据集成任务详情,点击操作列中的【详情】按钮,进行数据集成任务详情查看。
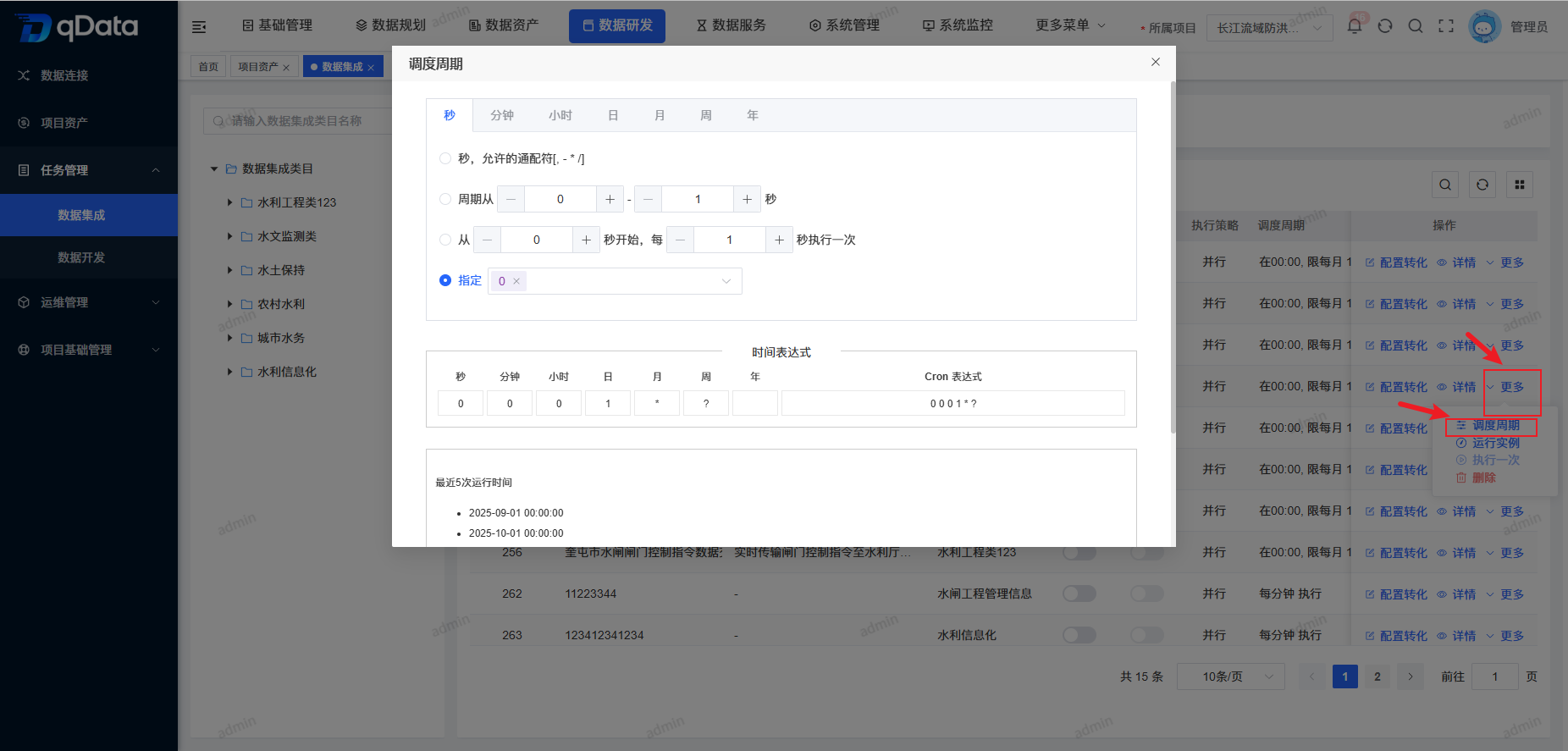
6、调度周期
选择需任务调度与执行的数据集成任务,点击操作列中的【更多】->【调度周期】按钮,在弹出框内填写相关信息,并点击【确定】按钮,系统将调度执行该数据集成任务。
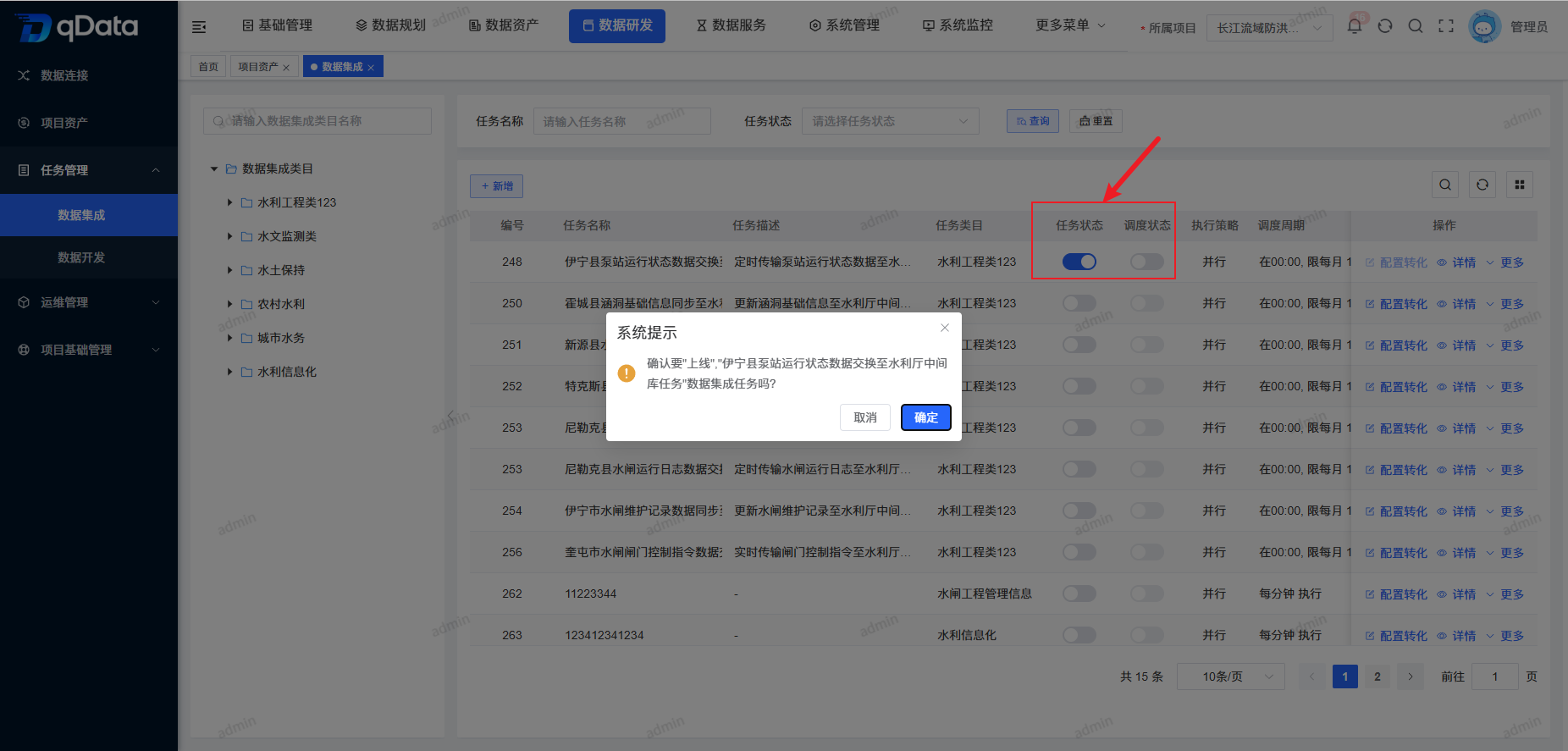
7、任务状态
选择需上线/下线的任务状态,在状态列中点击【开关】按钮,即可完成上线/下线操作。
8、调度状态
选择需上线/下线的调度状态,在状态列中点击【开关】按钮,即可完成上线/下线操作。
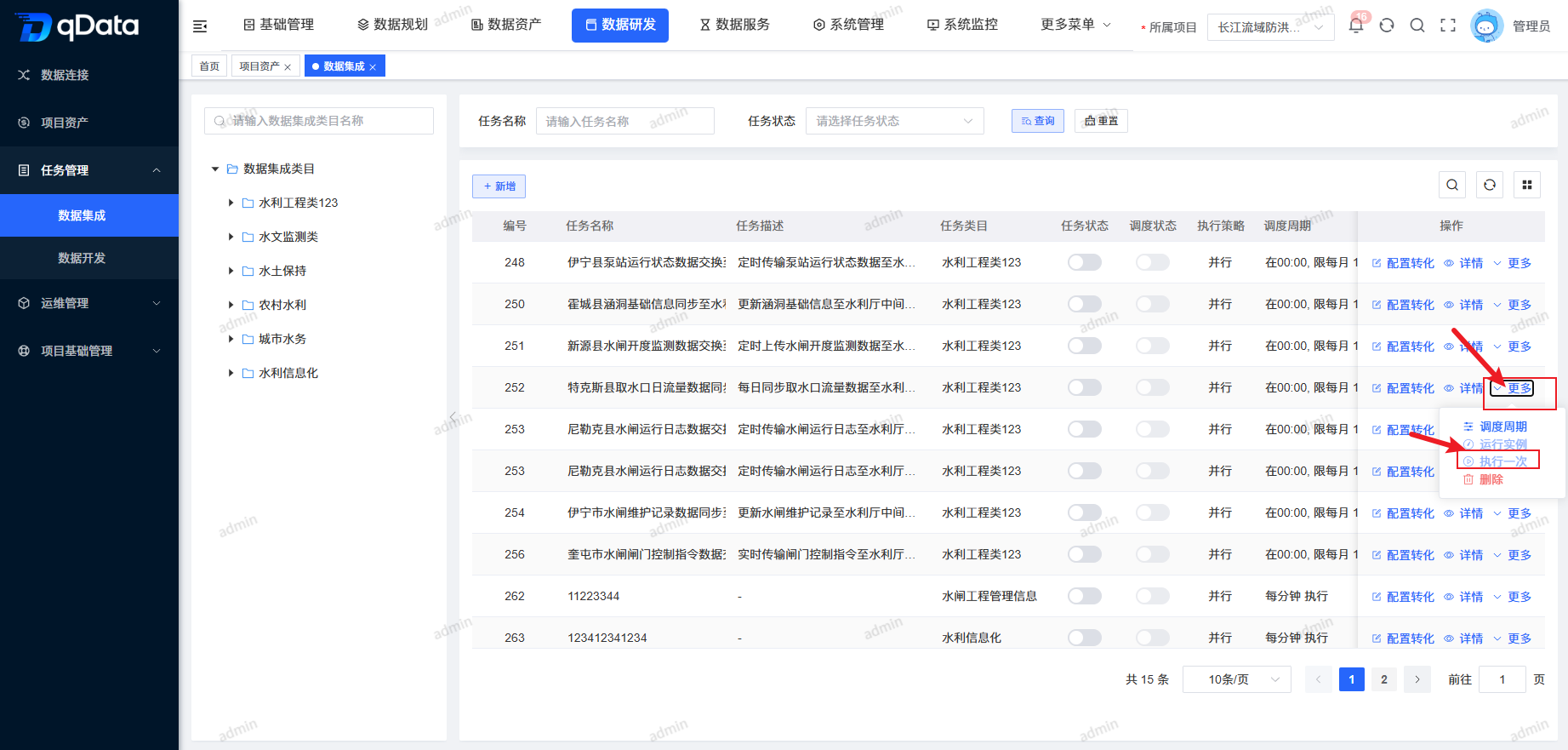
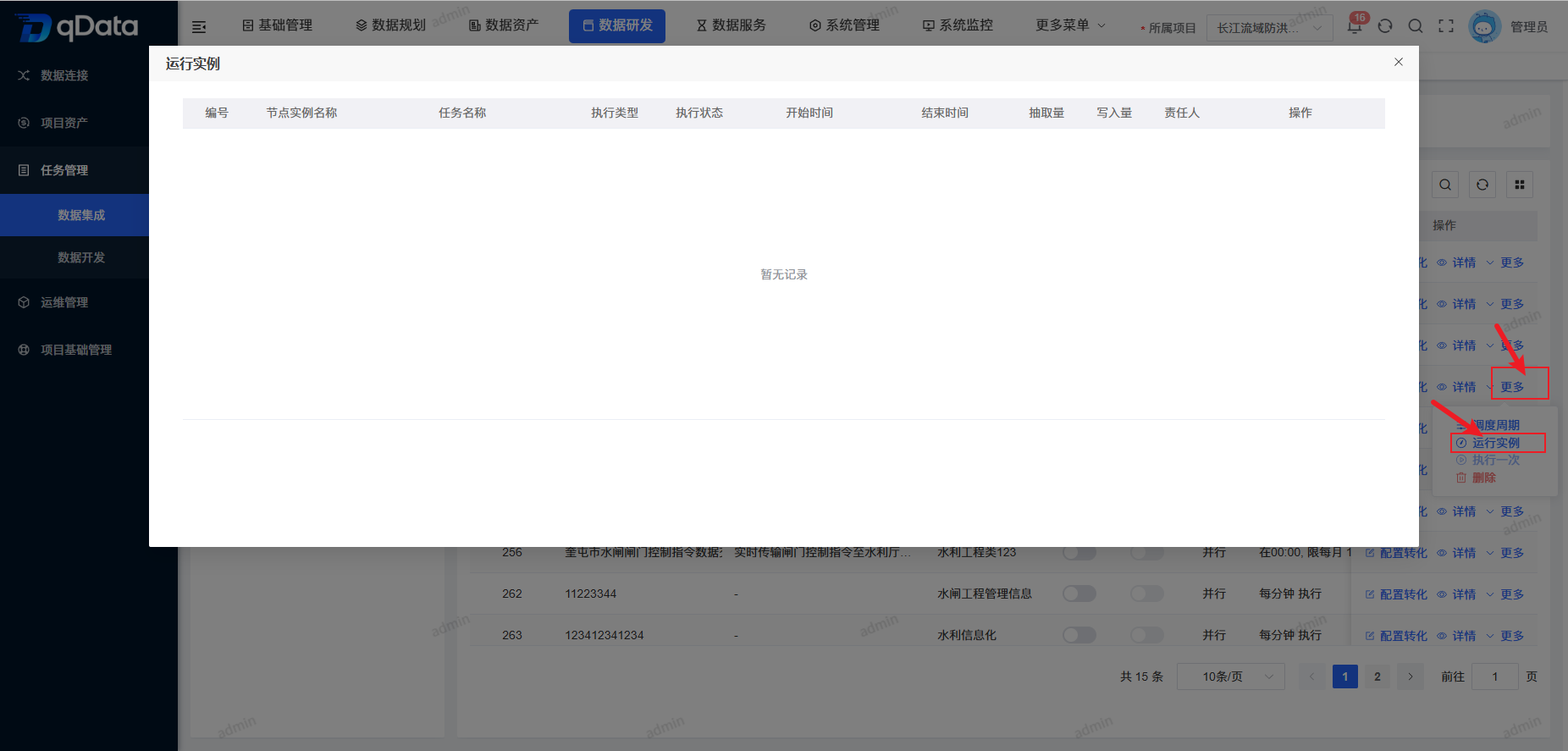
9、运行实例
选择需查看运行实例的数据集成任务,点击操作列中的【更多】->【运行实例】按钮,在出现的弹出框内查看。
10、执行一次
选择需执行一次的数据集成任务,点击操作列中的【更多】->【执行一次】按钮,系统将执行一次该任务,并提示相关信息。