性能说明
2025/6/18大约 7 分钟常见问题大数据平台数据中台性能瓶颈
一、数据中台与大数据平台
1. 什么是数据中台?
数据中台是企业构建统一数据资产、打通数据孤岛、服务业务系统的技术平台。它具备以下核心能力:
- 接入多种类型的数据源,包括结构化、半结构化、非结构化数据;
- 提供统一的数据治理、标准建模、权限管理与开发运维能力;
- 向前台系统统一输出数据服务,支持报表、分析、API 等多种形式;
- 构建企业级“数据资源池”,为多业务共享提供基础支撑。
简而言之,数据中台是“数据能力的集成与赋能平台”。
2. 什么是大数据平台?
大数据平台是为处理海量数据而设计的分布式计算和存储基础设施,通常包括以下核心组件:
- 计算引擎:如 Spark、Flink、Hive,用于批处理、流处理与交互查询;
- 存储系统:如 HDFS、HBase、Hive 表,分别用于文件存储、KV 存储与结构化存储;
- 资源管理与调度工具:如 Yarn、Kubernetes、DolphinScheduler 等;
- 监控与告警系统:用于保障平台运行安全与稳定性。
大数据平台的核心是“支撑高吞吐、可扩展、弹性处理的数据计算能力”。
3. 数据中台与大数据平台的交互
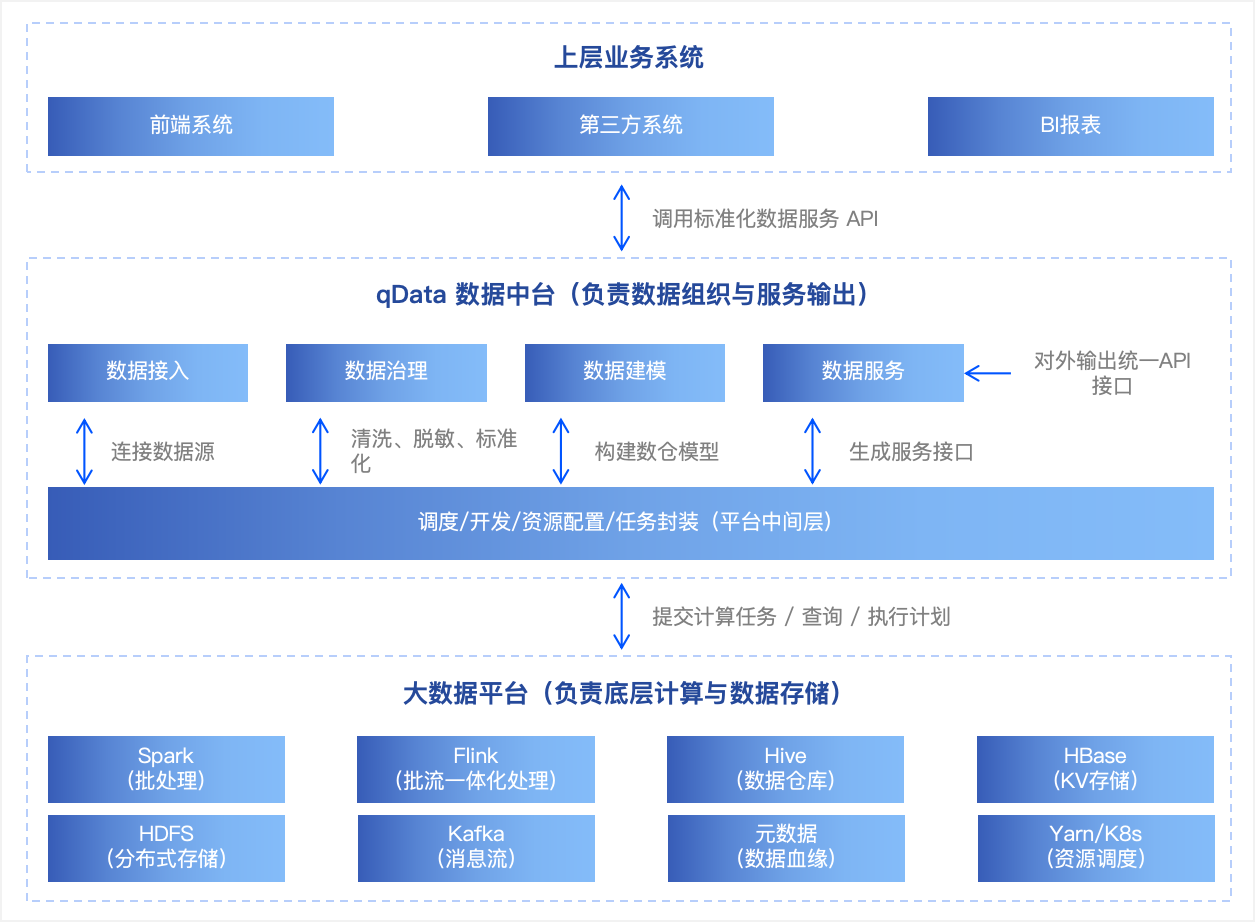
| 层级 | 系统/平台 | 职责描述 |
|---|---|---|
| 上层 | 上层业务系统 | 调用中台提供的接口获取结果数据,不直接访问底层数据平台 |
| 中间层 | qData 数据中台 | 负责组织数据源、建模治理、封装接口、管理任务调度,是“数据服务提供者” |
| 底层 | 大数据平台(Spark/Flink等) | 真正承担数据处理、计算任务,是“数据处理执行者”与“性能核心” |
🔍 重点突出
- 中台对接上层系统: 统一封装接口,简化业务系统对数据的访问复杂度;
- 中台调度下层平台: 根据用户开发的任务和配置,合理调度 Spark/Flink 等引擎执行;
- 性能调优重心在底层: 资源配置、数据模型设计、计算逻辑优化主要依赖大数据平台的调优;
- 中台平台支持配置化调用和统一入口: 是桥梁和控制中心,但不承担核心计算压力。
二、数据中台对任务性能可能产生影响的地方及应对方法
qData 本身并不直接参与底层大数据计算,但在任务配置、接口调用等方面,确实有一定性能影响因素,现归纳如下:
| 模块/环节 | 潜在性能影响 | 背后原因说明 | qData 的应对能力 |
|---|---|---|---|
| 任务资源参数配置 | 数据开发任务执行时间长,资源占满或失败 | Spark、Flink 等任务需要设置合理的 CPU、内存资源,配置过小则效率低 | qData 提供资源参数配置入口,支持不同任务类型使用差异化配置模板 |
| 第三方工具 API 封装方式 | 数据处理效率差,查询卡顿 | 第三方引擎 API 使用方式差异大,低效用法可能导致性能大幅下降 | qData 封装任务调用方式,提供推荐用法、最佳实践与文档引导 |
| 数据服务接口响应慢 | 页面加载慢,接口压力大 | 热点接口每次都查询大表,未缓存,系统压力剧增 | qData 支持设置缓存规则、接口限流、负载均衡等策略 |
| 系统部署架构选择 | 单节点性能瓶颈、难以扩展 | 单体架构部署时遇到并发瓶颈,难以支撑大访问量 | qData 支持微服务化部署,灵活拆分服务模块并支持水平扩展 |
三、大数据项目的性能瓶颈设计
1. 大数据平台的性能瓶颈主要在哪些地方?要如何应对?
qData 是调度者与组织者,真正承担大规模计算任务的是底层大数据平台,而这些平台在使用中常见如下性能瓶颈:
| 可能存在的瓶颈点 | 常见表现 | 原因说明 | 建议优化方式 | 责任归属 |
|---|---|---|---|---|
| 资源配置不足 | Spark/Flink 任务失败、执行缓慢 | 默认参数未区分任务类型,资源不足以支撑大任务计算 | 合理设置 executor CPU/内存,按任务等级分配模板 | 实施方或平台管理员 |
| 数据倾斜严重 | 某节点负载异常、任务运行慢 | 特定 key 数据过多集中,导致节点负载不均 | 添加随机因子(加盐)、热点值打散、预聚合 | 实施方数据工程师 |
| 表结构设计不合理 | 查询全表扫描、Join 非常慢 | 表未分区、索引缺失、采用低效存储格式 | Hive 使用分区表 + 列存(如 Parquet)、建索引 | 数仓建模人员 |
| 调度依赖复杂 | 整体调度链耗时长、易失败 | 任务拆分过细,依赖关系繁琐 | 合理合并任务、优化 DAG 链路结构 | 实施方调度人员 |
| 接口查大表未缓存 | 页面卡顿、接口失败 | 热点接口每次查询原始明细表,计算量大 | 使用缓存中间表或接口缓存机制 | 实施方或中台配置人员 |
2. 项目角色职责划分建议
为确保系统整体性能,应明确不同角色职责,各方协同优化:
| 项目关键环节 | 主要工作内容 | 由谁负责 | 原因说明 |
|---|---|---|---|
| 大数据平台部署与配置 | 安装 Spark/Flink/Hive 等,配置资源调度机制 | 客户或实施团队 | 由客户提供资源或由合作方代运维 |
| 资源调度与任务调优 | 设置每类任务的资源参数 | 实施团队 | 实施方掌握业务场景与任务特性,应进行合理资源设定 |
| 数仓建模与表结构设计 | 建表、分区策略、存储格式设计 | 实施方 + 业务方 | 模型需同时考虑业务和计算效率,双方需协同完成 |
| 数据接口设计与发布 | 输出 API 接口、设置缓存规则 | 实施方 + qData 使用方 | qData 提供工具与平台,调用逻辑由使用团队定义 |
| qData 平台部署与参数配置 | 系统架构设计、模块部署、配置优化 | 我们(qData 产品提供方) | 平台产品能力和参数配置需由我们提供完整支持 |
| 数据库读写优化(如 MySQL) | 部署主从结构、读写分离 | 客户 | 客户拥有数据库权限和基础设施资源 |
四、总结
- qData 本身并不直接执行大数据计算,系统架构稳定,性能表现良好;
- 真正影响性能的核心在于大数据平台的资源配置、数据结构设计和调用方式;
- qData 已提供丰富的性能参数配置能力,包括任务资源配置、API 缓存策略、微服务部署等;
- 建议客户在项目初期由实施方统一规划底层数据架构,并结合我们的平台能力,形成整体可控的性能方案;
- 我方也可根据客户实际需求有偿提供性能优化相关的技术支持与咨询服务,协助识别系统瓶颈并提供专业优化建议,确保 qData 在水利、制造、政务等复杂场景下稳定支撑业务数据需求。